I opened dreamina.capcut.com from my desk, ready to test the AI video model my whole feed had crowned the best of 2026. The page loaded two words. Coming Soon.
That was the moment this article started. For weeks I had watched cinematic clips roll past on X, each one captioned as proof that the AI video race was over. Native sound in the same file. One character holding across every cut. Camera moves that looked storyboarded. Faces so real they were unmistakable.
The tool itself would not open for me.
So this is not a paid review or a highlight reel. I pulled the official ByteDance documentation, the independent blind-vote benchmarks, the pricing pages of the providers that actually host the model, and the write-ups from creators who ran real generations. Where I judge output quality, I lean on those sources instead of pretending I tested every feature myself from a country where the product is blocked. I will tell you which claim rests on what, and by the end you will see why that Coming Soon page is the whole story in miniature.
My scorecard, up front
Here is where I land, before the detail, so you can decide how much of the rest you need.
| What I rated | Score | My read in one line |
|---|---|---|
| Innovation | ★★★★★ | Ahead of rivals on unified audio-video generation |
| Video quality | ★★★★☆ | Cinematic at its best, with weak spots it never shows you |
| Reference and prompt control | ★★★★☆ | The @ reference system is strong; fine pacing is not |
| Availability | ★★☆☆☆ | Blocked or gated across much of the world today |
| Value for money | ★★★☆☆ | No official global price, and the real bill climbs fast |
| Overall hype | Half earned | A strong model, oversold as something you can just go use |
Why my whole feed rated it a ten
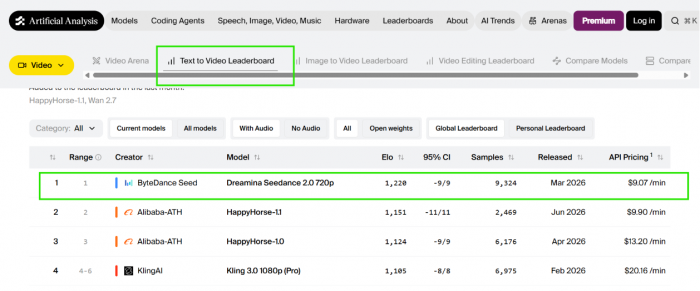
Seedance 2.0 arrived on 12 February 2026 from ByteDance's SEED lab, and it did not ease in quietly. Within days it sat at the top of the Artificial Analysis Video Arena, a leaderboard built on blind preference votes rather than marketing copy. In the categories that pair video with generated sound, it took first place outright.
The benchmark mattered. The benchmark is not what made it go viral.
What spread across social feeds were clips of recognisable faces. Famous actors and film characters, rendered in motion with sound, indistinguishable at a glance from a real shot. That realism did two jobs at once. It proved the model belonged in the same conversation as the strongest Western systems, and it lit a copyright fuse I will come back to later, because it is the reason my Dreamina page says Coming Soon.
Strip away the viral clips and four features did the actual convincing:
- Native audio produced in the same pass as the video, including dialogue with lip sync
- Multi-shot sequences that keep one character consistent across cuts
- An @ mention system for feeding in reference images, video clips, audio and camera style
- Motion and physics that held together better than most rivals did at launch
Under the clips, the raw spec sheet looks like this:
| The spec | The detail |
|---|---|
| Maker and launch | ByteDance's SEED lab, 12 February 2026 |
| Clip length | Up to fifteen seconds in a single generation |
| Resolution | 720p on free and base tiers, rising to 1080p and 2K on higher tiers |
| Reference inputs | Up to twelve per generation, each tagged with @ to assign its role |
| Audio | Native sound generated with the video, tuned for English dialogue |
| Model variants | Standard for final quality, Fast for quick iteration |
| Where to get it | ByteDance's own apps, with third-party providers filling the gaps |
The clips were strong enough that I needed to pull each promise apart and check it against evidence. That is the next section.
What Seedance 2.0 claims it can do
ByteDance's product page makes five headline claims. I set each against what the documentation states and what independent testers reported, then landed on a verdict.

| The claim | What the evidence shows | My verdict |
|---|---|---|
| Native audio | Docs describe a single pass that outputs synced dialogue, lip movement, background score and ambient effects. Testers confirmed the sound arrives aligned to the picture. | Holds up |
| Multi-shot storytelling | One prompt can output several shots with clean cuts while holding characters and setting stable. Reviewers built full hook-to-payoff sequences with it. | Holds up |
| Character consistency | Reference images lock a face or a product across angles and lighting. Independent testing rated its temporal consistency a real strength. | Holds up, within limits |
| Camera and lighting control | Docs promise director-level control of movement, lighting, shadow and motion. In practice control is mostly prompt-driven, and fine pacing stays coarse. | Partly true |
| Multimodal @ inputs | Up to twelve references per generation, spanning images, video clips, audio and style cues, each tagged with @ to assign it a role. | Holds up |
Native audio, the feature doing the heaviest lifting
The single sound track is the reason Seedance 2.0 tops the audio leaderboards. Most rivals still hand you a silent clip that needs sound design bolted on afterwards. Here the draft arrives with speech, sound effects, lip movement and a background score already lined up to the visuals.
One caveat the demos hide: the dialogue is tuned for English. Other languages exist, and their timing and lip sync are less dependable, which stings for anyone shipping campaigns outside English.
The @ reference system, the part that feels new
The control creators keep praising is the tagging workflow. Instead of describing a character in a paragraph and hoping, you upload a reference and tag it. In one generation you can hand the model up to twelve reference inputs: an image for the character, a clip for the camera move, a track for the audio rhythm and a frame for the lighting.
For animators who already work from pose sheets and style frames, this maps onto an existing habit and cuts iteration loops. It does not support custom fine-tuning of a character model, so a fixed brand mascot still has to be rebuilt through references every time you generate.
These claims mostly survive scrutiny. The sharper question is where they survive and where they quietly fall apart, and that splits the rest of this piece in two. I will start with the wins.
Where the hype actually holds up
Some of the noise is earned. The blind-vote arena and independent testing back these claims, not the marketing alone:
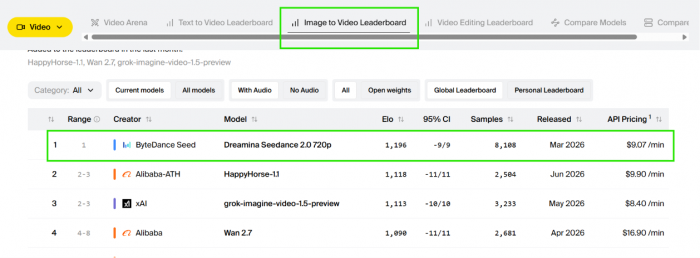
- Audio-native quality: first place in the Artificial Analysis arena categories that include generated sound, with a wide margin in image-to-video
- Character and temporal consistency: faces and objects hold their identity across frames without the morphing that wrecks weaker models
- Cinematic look: textures, lighting, surfaces and depth read as filmed rather than rendered in the strongest examples
- Reference-driven control: the multi-input @ system steers output more precisely than a bare text box ever could
If the story ended here, the hype would simply be correct. Two things stop it ending here. The first is whether the word best even survives when the leaderboard reshuffles every month. The second is what happens when you try to open and pay for the thing.
But is it actually the best?
Best is the word the demos lean on hardest, so it earns its own look. The honest answer shifted twice in three months, because this field refuses to sit still.
At launch Seedance 2.0 led the arena outright. By April an Alibaba model called HappyHorse-1.0 appeared and passed it in the categories without sound, while Seedance kept its lead in the ones with sound. Inside the same window OpenAI retired Sora, so a name that had anchored every comparison simply left the board. What counts as best depends on which column you read, and which week you read it. For a buyer that volatility is the real signal, because today's number one is a snapshot rather than a moat.
| The model | Its edge | The catch |
|---|---|---|
| Seedance 2.0 | Top of the audio categories, with strong reference control | Gated access and blocked face references |
| HappyHorse-1.0 (Alibaba) | Leads several of the no-audio categories | Its public product and access stay unclear |
| Kling 3.0 | Reliably available, with higher native resolution and multi-shot | A step behind on the audio-native look |
| Veo 3.1 (Google) | The one generating full synchronised dialogue rather than sound effects alone | Priced and gated inside Google's own tiers |
| Runway | The best fine control surface for real editing work | Off the top of the raw-quality board now |
So it leads a race with no stable finish line, and only for people who can reach it. That second condition is where the reality section starts.
The part the demo reels skip
This is the section almost no ranking article writes, because it does not help sell a subscription. It is the part that answers my opening screenshot. The wins above are what a demo shows you in thirty seconds. What follows is what the same tool shows you across a week of real work.
The legal retreat that put Coming Soon on my screen
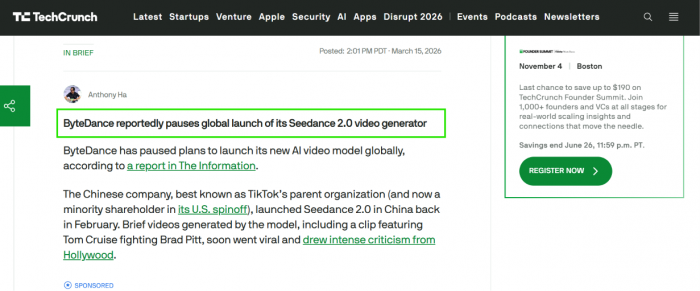
Remember those viral clips of famous actors. They worked too well. Industry coverage reported that in mid-March 2026, roughly a month after launch, cease-and-desist letters landed from Disney, Paramount, Warner Bros. and the Motion Picture Association over the use of their characters and likenesses. ByteDance paused the global rollout in response.
That pause is why my Dreamina page says Coming Soon. Access retreated toward ByteDance's home market, and much of the rest of the world was left waiting or locked out. India is one of those places.
The retreat also reshaped the product for people who can open it. To cut its legal exposure, ByteDance layered in aggressive content filters. Uploading a real human face as a reference is now blocked, including custom AI faces that never existed anywhere. Features such as attaching a specific voice to a specific face were switched off on the main platforms. The tool that went viral on realistic human likenesses now refuses most of them. For a marketer that means the exact trick that made the model famous, dropping a known face into a scene, is the one job it will no longer do.
What it actually costs, once you are in
Pricing is where the go-make-videos pitch gets slippery. ByteDance has not published an official global price sheet. Access is bundled into its own apps, and beyond that you pay whatever the third-party host charges.
On the API providers that carry it, representative rates sit around ten cents per second of standard video, a little under that for the faster tier. That reads cheap until you count the multipliers. The free and base tiers cap at 720p, which is softer than the 1080p and 2K clips that fill the demo reels. Pushing to 1080p roughly doubles credit use, and 2K can cost two to three times the base rate. Reference uploads and retries add more on top, and this is a model people retry often. Stack the resolution bump, the failed takes and the reference credits, and a single polished clip can cost several times what the per-second figure first suggested.
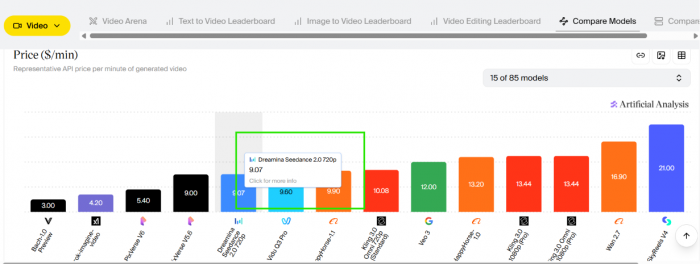
The headline number is small. The bill for a finished high-resolution clip is not.
The rough edges in the actual output
The demos are curated. Real generations carry the failure modes testers keep flagging.
| Weak spot | What actually happens |
|---|---|
| Hands and text | Fingers fuse or multiply, and on-screen text comes out garbled |
| Crowds and ensembles | Several distinct characters interacting drift out of consistency; one or two subjects hold far better |
| Fast motion | Quick action introduces distortion and objects that float or vanish |
| Clip length | Fifteen seconds is the ceiling, short for anything with a narrative |
| Control precision | Small prompt changes swing framing hard, so fixing one detail often means regenerating the whole shot |
| Speed and API | Standard generation can take one to two minutes for a five-second clip, and the developer API is still a public beta with rate limits and shifting behaviour |
Add these up and a pattern appears. Seedance 2.0 is a strong idea engine and an unreliable production line. That distinction decides who it is for, which comes right after one more comparison.
Marketing claim vs what you actually get
Here is the whole argument compressed into one view.
| The marketing line | What you actually get |
|---|---|
| Hollywood quality on tap | The best clips look filmed; the median clip needs retries and cleanup |
| Director-level control | Real control over references, coarse control over pacing and camera |
| Instant production-ready video | Fine for short social and ad drafts, shaky for reliable long-form delivery |
| The best AI video model | First in the audio categories, already passed in some no-audio ones by a newer rival |
| Use your own actors and faces | Real face references are now blocked by the content filters |
| Available to creators everywhere | Gated or blocked across much of the world after the rollout pause |

Who should jump in, and who should wait
The verdict is not one-size. It turns on where you sit and what you ship.
Worth opening today if you are
- In a supported region, making short cinematic pieces, social clips, ad drafts or product B-roll with native sound
- Working reference-first, with pose sheets or style frames to feed the @ system
- Able to absorb a higher retry rate in exchange for the audio-native look
- Prototyping or storyboarding, where a fast strong draft beats a slow perfect one
Better to wait if you are
- In a gated region like India, where the official platform will not open at all
- Shipping production-critical work that cannot tolerate breaking API changes or heavy retries
- Dependent on real human likenesses, or a fixed brand face the filters now block
- Building long-form video, where the fifteen-second ceiling forces constant stitching
The reasons trace straight back to the reality section above. The strengths are real, and so are the walls.
So, is the hype real?
So here is my call. The quality is real, and the product is not ready for most of the people being sold on it.
On blind votes with sound in the mix, Seedance 2.0 leads its field, and the consistency and cinematic look survive real testing. The native-sound generation is a capability rivals are still chasing. As engineering, it delivers what the demos promised.
The framing is where it falls down. It gets sold as the model that ended the race, the one anyone can go use. Right now it is a partial legal casualty. Access has retreated from most of the world, and the human-likeness trick that made it famous is switched off. You reach what remains through third-party providers rather than an open door. The benchmark says number one. The product says wait.
Which brings me back to where I started. The truest test of an AI model is not its Elo score. It is whether you can open the thing and make something.





